iOS本地缓存方案之YYCache源码解析
iOS持久化方案有哪些?
简单列举一下,iOS的本地缓存方案有挺多,各有各的适用场景:
NSUserDefault:系统提供的最简便的key-value本地存储方案,适合比较轻量的数据存储,比如一些业务flag。主要原因还是其底层是用plist文件存储的,在数据量逐步变大后,可能会发生性能问题。
存文件,归档:
无论是自己转换业务数据为二进制再writeFile,还是直接利用系统的
NSKeyedArchiver接口归档成文件,都属于文件存储的方案。优势是开发简单,业务可以自行控制单文件的存储内容以避免可能发生的性能问题。sqlite、FMDB:
底层利用到数据的存储方案,比较适用数据量大,有查询,排序等需求的存储场景,缺点就是开发略复杂一些。
CoreData、其他ORM方案:
CoreData感觉好像应用并不是很广泛?
Key-Value接口的缓存方案:
这里特指提供Key-Value形式接口的缓存库,底层缓存可能使用文件或者sqlite都有。本文讨论的
YYCache底层是混合使用文件+sqlite的存储方式。基于接口简便,性能优于NSUserDefault的特性,应该适用于大多数的业务场景,但是无法适用上面数据库类似的使用场景。
聊聊YYCache的优秀设计
这里其实yy大神本人在博文《YYCache 设计思路》中对其设计思路有比较详尽的介绍,建议大家可以先去读一读,本文就其相对于其他缓存库的一些优势点聊一聊。
高性能的线程安全方案
首先高性能是YYCache比较核心的一个设计目标,挺多代码逻辑都是围绕性能这个点来做的。
作为对比,yy提出了TMMemoryCache方案的性能缺陷。TMMemoryCache的线程安全采用的是比较常见的通过dispatch_barrier来保障并行读,串行写的方案。该方案我在上一篇《AFNetworking源码解析与面试考点思考》中有介绍。那么TMMemoryCache存在性能问题的原因会是因为其dispatch_barrier的线程安全方案吗?
答案应该在其同步接口的设计上:
1 | - (id)objectForKey:(NSString *)key |
TMCache在同步接口里面通过信号量来阻塞当前线程,然后切换到其他线程(具体代码在其异步接口里面,是通过dispatch_async到一个并行队列来实现的)去执行读取操作。按照yy的说法主要的性能损耗应该在这个线程切换操作,同步接口没必要去切换线程执行。
yy这边的思路是通过自旋锁来保证线程安全,但仍然在当前线程去执行读操作,这样就可以节省线程切换带来的开销。(不过我在YYCache的最新代码里看到的是普通的互斥锁,并没有用自旋锁,应该是后面又做了方案上的修改?)
除了加锁串行,dispatch_sync实现同步的方案是否可行呢?
除了yy提供的加锁串行方案,我们来看看前面介绍过的barrier并行读串行写方案是否也存在性能问题。如果使用该方案,同步接口可能是这样的:
1 | - (id)objectForKey:(NSString *)key |
经过demo验证,可以发现虽然是dipatch到一个concurrent_queue中执行,但是由于是sync同步派发,实际上并不会切换到新的线程执行。也就是说该方案也能做到节省线程切换的开销。
划重点: dispatch_sync不会切换调用线程执行,这个结论好像也是个面试考点?
那么该方案与加锁串行的方案相比,性能如何呢?
barrier实现并行读串行写 vs 互斥锁串行处理的性能比较
单线程测试
首先跑了下YYCache自带的benchmark,其原理是测试单线程做20000次读或者写的总耗时。其中TMCache new表示修改为dispatch_sync后的测试数据。
1 | =========================== |
从结论看,单线程用dispatch_sync的方案,比YYCache的锁串行方案要慢2倍多一点,比原始的信号量强行同步操作要快25到35倍。
所以开发过程中需要避免类似TMCache原始写法的同步接口实现方案。
多线程测试
display_barrier是并行读,串行写的方案,理论上在多线程并发的场景会更有优势,所以我尝试写了个多线程的benchmark来对比性能,代码如下:
1 | typedef void(^exec_block)(id key, id value); |
因为是并发执行,所以结束时间是通过dispatch_group来拿的。函数接收外部传入的exec_block作为输入,block内部执行具体的YYCache和TMCache的set/get方法。
这个测试方案存在一个问题,整个耗时大头在dispatch_group_async的派发上,block内部是否执行cache的get/set方法,对整体耗时结果影响不大。所以最终我也没有得到一个比较准确的测试结果,或许固定创建几个线程来做并发测试会更靠谱一些。
高性能的本地存储方案
除了多线程的高性能实现,YYCache在本地持久化如何提高性能也有个小策略。核心问题应该就是二进制数据从文件读写和从sqlite读写究竟哪个更快?sqlite官网有一个测试结论:
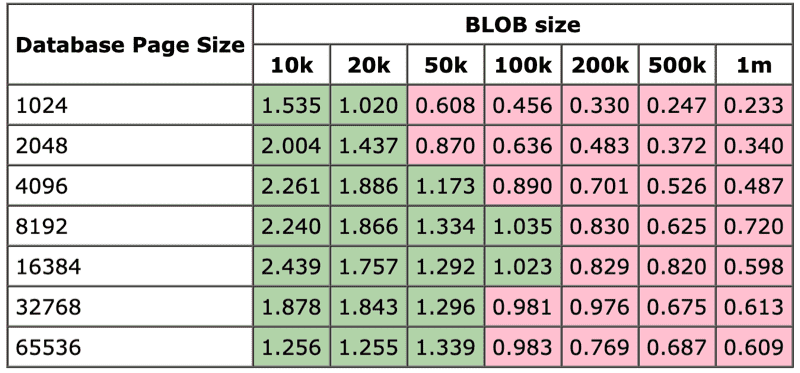
表格中数值表示存文件耗时除以存数据库耗时,大于1表示存数据库更快,表示为绿色。
基于这个结论和自己的实测结果,YYCache采取的方案是大于20k的采取直接存储文件,然后在sqlite里面存元信息(比如说文件路径),小于20k的直接存储到sqlite里面。
数据完整性保障:
对于有关联的数据,存储时一定需要保障其完整性,要么全成功,要么全失败。比如YYCache在存储文件时,存在数据库的元信息和实际文件的存储就必须保障原子性。如果云信息存储成功,但是文件存储失败,就会导致逻辑问题。具体YYCache代码如下:
1 | if (![self _fileWriteWithName:filename data:value]) { |
这里可以看到,只有文件存成功了才会存数据库元信息,如果数据库元信息存失败了,会去删除已经存储成功的文件。
我们业务开发存储关联数据的时候,也需要注意这个逻辑。
缓存淘汰策略
除了性能之外,YYCache也新增了一些实用功能。
比如LRU算法,基于存储时长、数量、大小的缓存控制策略等。
LRU算法采用经典的双链表+哈希表的方案实现的,很适合不熟悉的同学参考学习,这里就不展开了。

- 本文链接:http://www.luoyibu.cn/posts/10712/
- 版权声明:本博客所有文章除特别声明外,均采用CC BY-SA 4.0许可协议。转载请注明出处!